Web scraping in Go using Colly and MongoDB
I’ve just recently started learning Go. So far I’ve been working through the Exercism track. While this is great to get a holistic understanding of the different concepts, I’ve been itching to dive deeper and make use of Go in a more real-life projects. As an engineer I’ve been thrown into the deep end many times and have found that after establishing some theoretical understanding, learning through example is the best way to grasp something new quickly. This post is the start of a series where I dive deeper into Go and Go libraries.
First on my list is to create a web scraper. Web scraping is the process of extracting information and data from web sites using automated tooling. Data on websites are often unstructured and web scraping helps to collect this data and structure it into usable formats for the purposes of various applications.
For this writeup, I am going to use an arbitrary example of web scraping Moneyweb for JSE stocks directors’ dealings. The idea behind this is that insiders buying large amounts of shares in a company, can lead to an increase in share price. While following the lead of insiders will never replace diligent research, analyzing these trends could produce some interesting results. We only focus on the scraping part here.
Go-based web scrapers
Looking at Awesome Go, there are a few options for Go web scraper frameworks. Two of the most mature ones are Colly and dataflowkit. Some other interesting ones, not on the list are also Ferret and Selenium (actually a WebDriver client, but can be used to scrape complicated dynamic websites with JS, etc).
While they all seem good, off a first glance, Colly seems to be the easiest to get going and the post popular. For the sake of this simple example, and to prevent analysis paralysis (which is a whole topic on its own) I am going to stick with Colly for now.
Installing Colly
Colly is very simple to install and only has the Go programming language as a prerequisite. Running the following will also update go.mod and create go.sum accordingly.
$ go mod init <project/module path>
$ go get -u github.com/gocolly/colly/...
Basic Collector Skeleton
Once Colly has been installed, the next step is to create a basic skeleton application that is capable of reaching a website using Colly. We do this by creating a new file main.go and modifying the basic example to point to MoneyWeb instead. We then point the scraper to visit the page of Sibanye Stillwater (SSW), a commodity mining stock. (There are multiple other examples at colly/_examples).
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(
// Visit only domains: moneyweb.co.za, www.moneyweb.co.za
colly.AllowedDomains("moneyweb.co.za", "www.moneyweb.co.za"),
)
// Before making a request print "Visiting ..."
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL.String())
})
// Start scraping on https://moneyweb.co.za
c.Visit("https://www.moneyweb.co.za/tools-and-data/click-a-company/SSW/")
}
$ go run main.go
Visiting https://www.moneyweb.co.za/tools-and-data/click-a-company/SSW/
This confirms that Colly is working as expected and we can now move on to more specific scraping.
Colly’s main entity is the Collector object. The Collector manages the network communication and is responsible for executing different callbacks. The Collector is initalized above as follows:
c := colly.NewCollector(
colly.AllowedDomains("moneyweb.co.za", "www.moneyweb.co.za"),
)
Colly supports multiple different callback functions, which can be attached to a Collector for the purposes of controlling a collecting job. These are functions which are executed on errors, HTML elements, requests, responses, etc. The Colly documentation has more information about the specifics of each one. Callbacks have the following call order:
OnRequest >> OnError (if error) >> OnResponse >> OnHTML >> OnXML >> OnScraped
Defining an appropriate data structure
In order to scrape a specific site, we need to visually inspect the page and determine an appropriate struct to use in order to the store the information. For this example, we want to collect the last ten directors dealings. This includes the fields DATE, BENEFICIARY, DEAL TYPE, VALUE, VOLUME and PRICE.
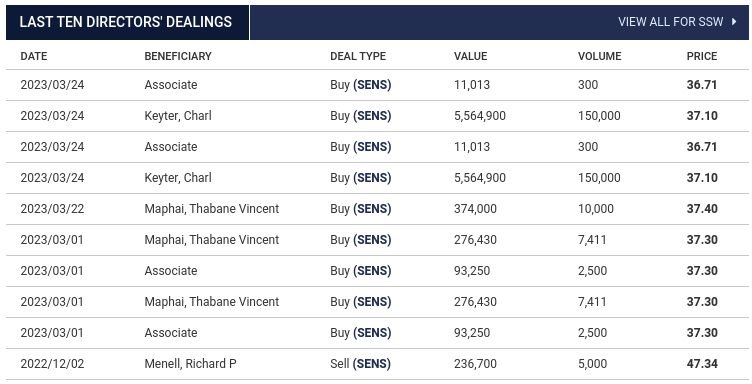
We therefore define a struct to match this, with the correct JSON formatting:
// Define the LastTenDirectorsDealings struct
type LastTenDirectorsDealings struct {
StockCode string `json:"stock_code"`
Date string `json:"date"`
Beneficiary string `json:"Beneficiary"`
DealType string `json:"deal_type"`
Value int `json:"value"`
Volume int `json:"volume"`
Price float32 `json:"price"`
}
Analyzing the page source and collecting the data
After defining a structure, we can now inspect the source of the page we want to scrape and determine which HTML elements contain our required information.
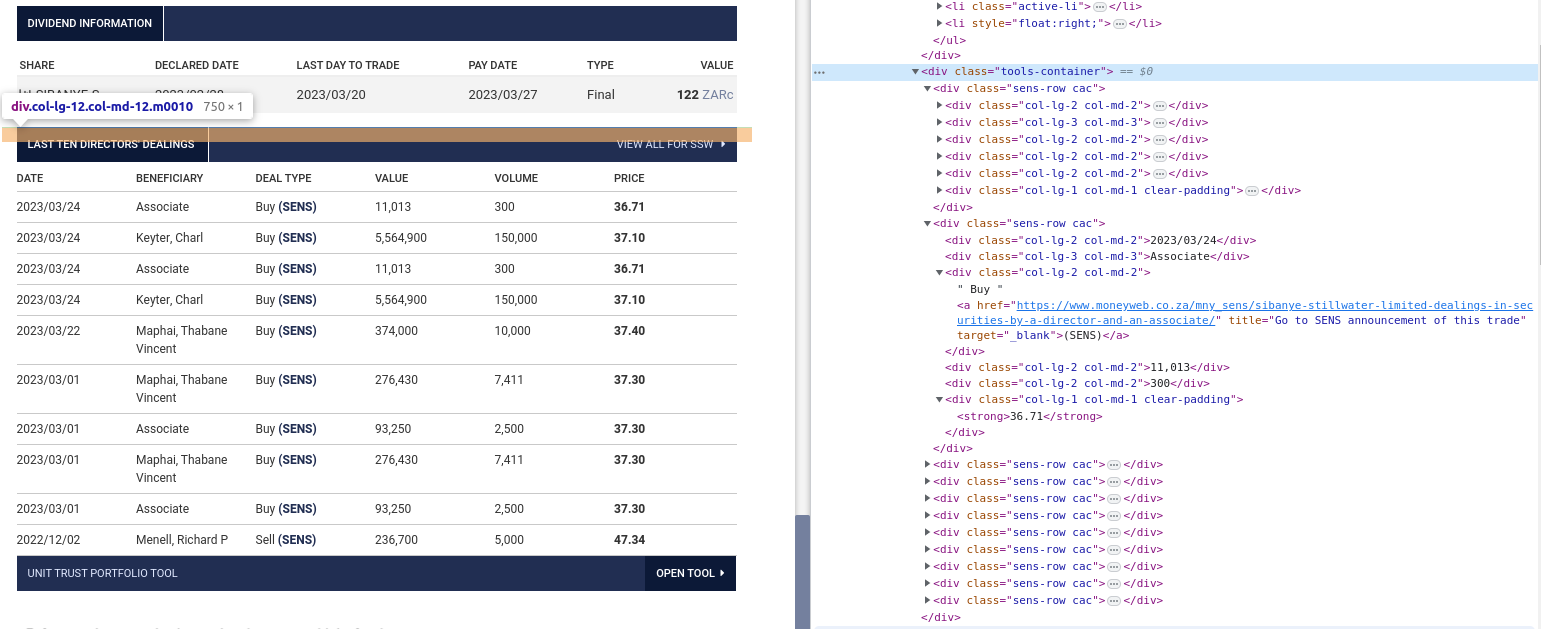
We can now see that the values we are looking for are within the <div class=sens-row cac> element rows. Then each value is either under a <div class=col-lg-2 col-md-2> (DATE, DEAL TYPE, VALUE and VOLUME), <div class=col-lg-3 col-md-3> (BENEFICIARY) or <div class=col-lg-1 col-md-1 clear-padding> (PRICE) column. We can use the following logic to extract all the values and populate the JSON struct:
// Set up the callback function to handle the HTML response
c.OnHTML(`div[id=cac-page]`, func(e *colly.HTMLElement) {
// Extract the required data from the HTML elements
e.ForEach(".sens-row.cac", func(_ int, el *colly.HTMLElement) {
// Skip headings row
if el.Index > 1 {
dealings := LastTenDirectorsDealings{
StockCode: "SSW",
}
// We know that DATE, DEAL TYPE, VALUE and VOLUME are all under
// .col-lg-2.col-md-2 elements. Work through each element accordingly.
el.ForEach(".col-lg-2.col-md-2", func(_ int, el_col *colly.HTMLElement) {
switch el_col.Index {
case 0:
dealings.Date = el_col.Text
case 1:
dealings.DealType = el_col.Text
case 2:
value, err := strconv.ParseInt(strings.Replace(el_col.Text, ",", "", -1), 10, 0)
if err != nil {
log.Fatalf("Failed to convert element: %v", err)
}
dealings.Value = value
case 3:
volume, err := strconv.ParseInt(strings.Replace(el_col.Text, ",", "", -1), 10, 0)
if err != nil {
log.Fatalf("Failed to convert element: %v", err)
}
dealings.Volume = volume
}
})
// We know that BENEFICIARY is the only one under a
// .col-lg-3.col-md-3 element.
dealings.Beneficiary = el.ChildText(".col-lg-3.col-md-3")
// We know that PRICE is the only one under a
// .col-lg-1.col-md-1.clear-padding element.
element_text := el.ChildText(".col-lg-1.col-md-1.clear-padding")
price, err := strconv.ParseFloat(strings.Replace(element_text, ",", "", -1), 32)
if err != nil {
log.Fatalf("Failed to convert element: %v", err)
}
dealings.Price = float32(price)
// Convert the struct to JSON
jsonData, err := json.Marshal(dealings)
if err != nil {
log.Fatalf("Failed to marshal JSON: %v", err)
}
// Print the extracted data in JSON format
fmt.Println(string(jsonData))
}
})
})
Which yields the following results:
{"stock_code":"SSW","date":"2023/03/24","Beneficiary":"Associate","deal_type":"\nBuy (SENS)\n","value":11013,"volume":300,"price":36.71}
{"stock_code":"SSW","date":"2023/03/24","Beneficiary":"Keyter, Charl","deal_type":"\nBuy (SENS)\n","value":5564900,"volume":150000,"price":37.1}
{"stock_code":"SSW","date":"2023/03/24","Beneficiary":"Associate","deal_type":"\nBuy (SENS)\n","value":11013,"volume":300,"price":36.71}
{"stock_code":"SSW","date":"2023/03/24","Beneficiary":"Keyter, Charl","deal_type":"\nBuy (SENS)\n","value":5564900,"volume":150000,"price":37.1}
{"stock_code":"SSW","date":"2023/03/22","Beneficiary":"Maphai, Thabane Vincent","deal_type":"\nBuy (SENS)\n","value":374000,"volume":10000,"price":37.4}
{"stock_code":"SSW","date":"2023/03/01","Beneficiary":"Associate","deal_type":"\nBuy (SENS)\n","value":93250,"volume":2500,"price":37.3}
{"stock_code":"SSW","date":"2023/03/01","Beneficiary":"Maphai, Thabane Vincent","deal_type":"\nBuy (SENS)\n","value":276430,"volume":7411,"price":37.3}
{"stock_code":"SSW","date":"2023/03/01","Beneficiary":"Associate","deal_type":"\nBuy (SENS)\n","value":93250,"volume":2500,"price":37.3}
{"stock_code":"SSW","date":"2023/03/01","Beneficiary":"Maphai, Thabane Vincent","deal_type":"\nBuy (SENS)\n","value":276430,"volume":7411,"price":37.3}
{"stock_code":"SSW","date":"2022/12/02","Beneficiary":"Menell, Richard P","deal_type":"\nSell (SENS)\n","value":236700,"volume":5000,"price":47.34}
Storing the results in a MongoDB database
Once the results have been collected, we need to store the data for further processing. This can be done using a variety of different options such as a CSV file or a database. In this example we make use of MongoDB to store the results. MongoDB is a NoSQL database, that uses JSON-like documents and allows for creating aggregation pipelines which we can use to analyze the data further.
Integrating MongoDB into Go is relatively simple. We start by importing the relevant Mongo drivers:
import {
...
"go.mongodb.org/mongo-driver/mongo"
"go.mongodb.org/mongo-driver/mongo/options"
}
Then we establish the appropriate connection to our database. This can be a local MongoMD database or one hosted on the cloud, such as MongoDB Atlas, which we use here.
// MongoDB Atlas connection settings
mongoURI := "mongodb+srv://<user>:<password>@<collection>.mongodb.net/<database>retryWrites=true&w=majority"
// Connect to MongoDB Atlas
client, err := mongo.NewClient(options.Client().ApplyURI(mongoURI))
if err != nil {
log.Fatalf("Failed to create MongoDB client: %v", err)
}
ctx, cancel := context.WithTimeout(context.Background(), 10)
defer cancel()
err = client.Connect(ctx)
if err != nil {
log.Fatalf("Failed to connect to MongoDB Atlas: %v", err)
}
defer client.Disconnect(ctx)
// Access the database and collection
db := client.Database("<database>")
collection := db.Collection("<collection>")
After the web data is scraped and the JSON struct is populated, we can add it to the cluster with:
// Insert the data into MongoDB
_, err = collection.InsertOne(ctx, dealings)
if err != nil {
log.Fatalf("Failed to insert data into MongoDB: %v", err)
}
Source code
The full source can be found on my GitHub: jse_directors_dealings_scraper